Redundancy in Cabling: A Must-Have for Any Network
Today, redundancy is the de facto standard for any network cabling system, and there are a variety of ways to accomplish it.
 Years ago it seemed as if disaster preparedness and redundant cabling systems were considered forward-thinking (and something of a luxury) for many network and data center owners and operators. Today, however, we rarely hear anyone touting redundancy, as it essentially has become the de facto standard for any network cabling system – from the LAN to the data center and beyond. Let’s take a closer look at redundancy, why it has become so prevalent, and some of the various ways it can be accomplished.
Years ago it seemed as if disaster preparedness and redundant cabling systems were considered forward-thinking (and something of a luxury) for many network and data center owners and operators. Today, however, we rarely hear anyone touting redundancy, as it essentially has become the de facto standard for any network cabling system – from the LAN to the data center and beyond. Let’s take a closer look at redundancy, why it has become so prevalent, and some of the various ways it can be accomplished.
A Safe Haven
While the term “safe haven” is in itself a redundant idiom (what kind of haven would it be, if it weren’t safe?), cabling redundancy is critical to keep a network safe during a single cable failure in any link. In other words, cabling redundancy allows the network to remain available and avoid downtime.
Avoiding downtime has always been the goal of any network and data center owner, but when we consider that every transaction, task, and communication now occurs digitally over a network, it has become vital to business success as consumers expect access to information at all times.
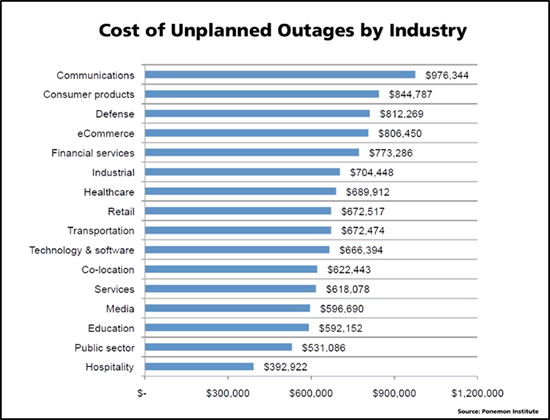
The extent to which a business can endure downtime really depends on how critical the network is to day-to-day (or even second-to-second) operations and to what level the revenue model depends on the ability to maintain network availability. Think of a financial institution, for example. With all monetary transactions made digitally, and trading floor environments demanding turnaround in milliseconds, it’s no wonder that the financial sector places the average loss per downtime incident at $504K[1]. One study placed the cost of an outage for financial services at nearly $775K, with e-commerce, defense, consumer products, and communications sectors stating even higher outage costs[2].
 While the financial impact of downtime is staggering, with more devices than ever residing on the network – everything from surveillance cameras and building automation devices to transportation systems, medical devices, and government intelligence systems –avoiding downtime is no longer just about the ability to make monetary transactions or access the Internet. Depending on the critical nature of the system or device, it now has a direct correlation to public safety and security.
While the financial impact of downtime is staggering, with more devices than ever residing on the network – everything from surveillance cameras and building automation devices to transportation systems, medical devices, and government intelligence systems –avoiding downtime is no longer just about the ability to make monetary transactions or access the Internet. Depending on the critical nature of the system or device, it now has a direct correlation to public safety and security.
Many factors can cause downtime, such as human error, power outages, equipment failure, security attacks, and natural disasters. Although some causes are unavoidable, most data centers today are designed with redundant systems, including primary and secondary power, cooling, and switching. However, for any network to truly be redundant, the cabling that forms the links between active equipment must also be redundant. Even in less-critical environments that may not have a high level of redundant facilities systems, cabling redundancy is almost always deployed for the network.
A Two-Way Street
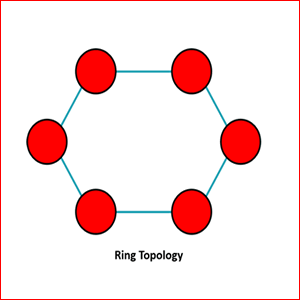
Cabling redundancy between active network nodes essentially means that data transmission can take multiple paths. Redundancy can be achieved using a ring topology, where equipment is connected in such a way that the last piece of equipment is connected to the first, allowing data transmission to travel in the opposite direction if a link within the ring fails. This type of redundancy is most often seen in a campus or LAN environment or in an outside plant application such as when connecting a data center facility to a disaster recovery site. One consideration in these environments is to ensure that the diverse cable paths also have physical separation. Redundant cables that run adjacently within the same pathways, either outside between buildings or within the building, are at risk of failing redundancy if the pathway itself becomes damaged.
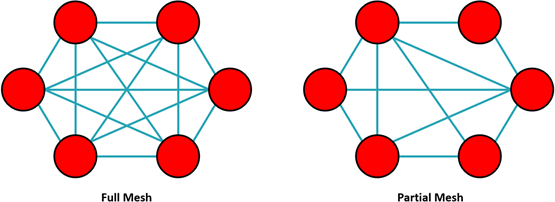
Within the data center, redundancy can be achieved by interconnecting nodes with multiple parallel cables. Two cables between nodes provide one level of redundancy, three provide two levels, and so on. The latest best practice in redundancy is to deploy a rapid-spanning tree protocol, which provides the fastest recovery time by using algorithms that determine which transmission paths are the most reliable. Well suited for more complex networks and data centers, a rapid-spanning tree protocol uses a mesh topology. In a full mesh topology, every network node is connected to every other network node. In a partial mesh, some nodes may connect to all other nodes while others connect to only two or more other nodes. Full mesh topologies are obviously more redundant than partial, and they are, therefore, more often seen in critical backbone data center links.
Down to the Wire
Redundant cabling may seem somewhat straightforward, but there are a few considerations when it comes to deploying the cables themselves, including distance limitations, space, and manageability.
When deploying a redundant cabling system, especially a mesh topology where several nodes connect to several other nodes, it is important to consider the distance limitations for a given bandwidth and application to ensure that the data transmission between each node remains reliable. Redundancy doesn’t make much sense if the data cannot properly reroute to another node; therefore, it is imperative to choose the right type of cabling. For example, an OM2 multimode fiber will only transmit 10Gb/s to about 100 meters, while more advanced OM3 will transmit 10Gb/s to 300 meters and OM4 will transmit to about 550 meters.
With redundant fiber cabling systems, it is also imperative to stay within optical insertion loss budgets to ensure proper data transmission. The length and number of mated connections within a channel all contribute to link loss, and higher speeds have more stringent loss requirements. Achieving full redundancy can require deploying longer cable lengths to make sure that every node connects to every other node. These longer cable lengths can be difficult to deploy and manage. Accordingly, many data centers deploy shorter, more manageable cable lengths by incorporating distribution points or cross-connects via patch panels between nodes. Unfortunately, this adds more mated connections and link loss within the channel. The use of specially qualified low-loss fiber connectors can help support multiple mated connections for flexibility over a wide range of distances and configurations while remaining within the loss budget.

Data center cabinets, such as Siemon’s VersaPOD, that offer vertical Zero-U space on either side of the equipment mounting area are ideal for routing and managing high-density, redundant cabling from active equipment.
Another consideration with redundant cable systems is the amount of pathway space between areas of the data center and within equipment cabinets themselves. You can imagine that running multiple parallel cables to and from each node results in much higher cabling densities. It is important to choose cable managers and cabinet and patch-panel solutions that offer ample space to support the cabling while enabling easy access and proper cable management. For example, in cabinets that offer vertical zero-U space on either side of the equipment mounting area, the zero-U space can be used for routing cables from the right and left of the equipment into diverse, redundant cable pathways.
Another consideration for redundant cabling is color coding. When the time comes to trace and troubleshoot faults that occur within the cabling system, color coding can help to clearly differentiate and identify each redundant cabling path. Color coding can be easily achieved using different cable jacket colors or even color-coded cable clips that are easily field-attachable to cables.
A Means to an End
Regardless of your business, downtime in today’s world comes with significant costs and potentially even worse consequences. While highly redundant cabling systems are the norm for any service provider, e-commerce outfit, financial institution, or defense department where downtime is simply not an option, every network and data center should have some level of cable redundancy. It’s no longer a nice-to-have option.
Understanding the various ways to deploy redundant cabling systems and the key considerations can go a long way in making sure you don’t get caught without an alternate route to keep your data flowing.
[1] 2014 Avaya Network Downtime Study
[2] 2013 Cost of Data Center Outages, Ponemon Institute
Author Betsy Conroy is global marketing communications manager for Siemon.





