Ethernet Data Rate Progression
The debate continues but it is clear that by 2017, we will have a standard for 400G Ethernet. Lisa Huff does a reality check on Ethernet data rate progression over the next five years and the connector companies building prototypes for possible 400G solutions.
 Computer networks are on the cusp of a revolutionary change. Software-defined networking (SDN) promises to drastically reduce the number of network elements as well as transform them into programmable units that are more focused on enabling applications. But we are not there yet. Over the next five years, we expect to see increased adoption of 10G and 40G Ethernet inside the data center. InfiniBand (IB) and Fibre Channel (FC) will see incremental growth – IB in the high-performance computing (HPC) sector and FC in the confines of the backend of the storage area network (SAN). Eventually, as SDN starts to transform the network (well beyond the next five years), we may see FC fade away as storage arrays and networks give way to storage within the servers. For this reason, we focus our attention here on the next data rates for Ethernet.
Computer networks are on the cusp of a revolutionary change. Software-defined networking (SDN) promises to drastically reduce the number of network elements as well as transform them into programmable units that are more focused on enabling applications. But we are not there yet. Over the next five years, we expect to see increased adoption of 10G and 40G Ethernet inside the data center. InfiniBand (IB) and Fibre Channel (FC) will see incremental growth – IB in the high-performance computing (HPC) sector and FC in the confines of the backend of the storage area network (SAN). Eventually, as SDN starts to transform the network (well beyond the next five years), we may see FC fade away as storage arrays and networks give way to storage within the servers. For this reason, we focus our attention here on the next data rates for Ethernet.
Where 100G Stands
100G deployments have been mostly in carrier networks – connecting data centers and central offices. But over the next five years, there will be large growth inside data centers as well. The need to change the data center network from a hierarchal one to a leaf-spine or more meshed one has arisen from the ever-increasing need for compute and storage access and the use of server virtualization. Now that many applications can run on one server, if that server gets overloaded, virtual machines (VMs) need to move to another server quickly – four hops through the network is not quick, so network architecture is changing to accommodate the mobility of VMs. As a consequence, what used to be just a client-server, standard, three-tier network is starting to look like an HPC cluster.
With the need for server density comes blade servers, and while they have not been adopted as quickly as anticipated, their installation rate will increase over the next five years. The use of blade servers will help facilitate mobility of VMs as well as transitioning into an SDN model. And with SDN, the idea of top-of-rack (ToR) or end-of-row (EoR) switching architectures will become obsolete, and the switching SDN controller will be incorporated into the software. The full implementation of this, however, is beyond the scope of this article; in the interim, we still see healthy growth of both ToR and EoR architectures in the near term.
Data center Ethernet server connections are currently transitioning from Gigabit Ethernet to 10G, which in turn is pushing the access, aggregation/distribution, and core switches to 40G and 100G. In 2014, the majority of data center severs are still connected with 1G Ethernet, but in 2015, the majority will be 10G. SFP modules are used for Gigabit Ethernet connections to servers, though most of the server connections will remain copper RJ45 ones. As they move to 10G, the majority will remain copper with either RJ45 CAT6A or SFP+ DACs.
With Ethernet data rate progression fueled by server network connection upgrades and access switch locations closer to servers via ToR or EoR configurations, the aggregation/distribution portion of the network is transitioning from copper to fiber. Actually, this phenomenon started even with 1G connections at servers because the 10GBASE-T 100m (or more than 10m) switch-port took so long to materialize. But now, with 10GBASE-T or 10GBASE-CR4 (using copper twinax) connections at the server, the uplinks are either multiple 10GBASE-SR (using LOMF) or 40GBASE-SR4 (using LOMF). This is where fiber will gain most of its momentum.
While these links will be mostly 10G or multiple 10Gs to start, by 2019 there will be a healthy market for 40G connections in this part of the network. Data center 10G optical transceivers will use SFP+. CFP and QSFP+ modules, AOCs, and DACs will be used for 40G, but QSFP+ is expected to take over in the long term. For 100G optical transceivers, there are six form factors – CXP, CFP, CFP2, CFP4, CPAK, and QSFP28. Since Cisco owns and makes the CPAK, it will get a large share of the market over the next five years. However, the QSFP28 is expected to dominate switch connections from other equipment manufacturers. In fact, many of the top transceiver manufacturers have decided to only support certain variants in some of these form factors because they see them as transient products. The table below shows the plan.

Short-reach optical variants will continue to dominate the data center since the majority of connections remain less than 50m. However, there is still a need for a cost-effective option for those few links that are longer than 150m. There are four multi-source agreements (MSAs) now vying for this space—100G CLR4 Alliance, CWDM4, OpenOptics, and PSM4. This represents the positioning of the vendor community when it comes to how to address this part of the market. Which solution will ultimately win is up in the air at this point because none have shown a compelling cost advantage over the existing LR4 variant or against each other.
Another emerging trend is to develop a 25GBASE-T connection for ToR (or EoR, for that matter) switch-to-server. There is a call for interest (CFI) in front of the IEEE 802.3 task force now that is being spearheaded by Microsoft. We believe that this will take hold in large Internet Data Centers (IDCs) within the next five years. In fact, Microsoft, Mellanox, Arista Networks, Broadcom, and Google recently formed a 25G Ethernet Consortium to move this along.
400G Plans
The IEEE P802.3 400GbE Task Force has now met three times. The objectives have been solidified and work has begun on possible implementations. Objectives include the following:
- At least 100m over MMF
- At least 500m over SMF
- At least 2km over SMF
- At least 10km over SMF
The ultimate goal would be to have 400G serial, but none of the technical experts believe this is achievable anytime soon. Some of the first designs are based on 25G signaling, which is the current state-of-the-art option. One of these is the CDFP.
The CDFP-MSA is currently a mechanical specification. The form factor is intended to support five meters of direct-attach copper (DAC) cables, 100m of multi-mode fiber, 500m on parallel SMF, and 2km of duplex SMF. The design is based on 25G per lane, so 16 transmit lanes and 16 receive lanes, to get to 400G. With the current design, the front-panel density can be as high as 13 ports or 5.2Tb/s. Any of the current technologies that are being used to support 25G are appropriate for this form factor as well. These include CWDM, VCSEL, and silicon photonics. A picture of the concept is shown below.

Figure 1: CDFP Form Factor (Courtesy CDFP MSA Group)
Subsequent designs are expected to be based on 50G or 100G serial, many of which are before the task force for review now.
Market Opportunities for 100G and 400G
The near-term market opportunity is 100G. Below is our overall forecast for 100G data center ports. These include all copper and fiber form factors.
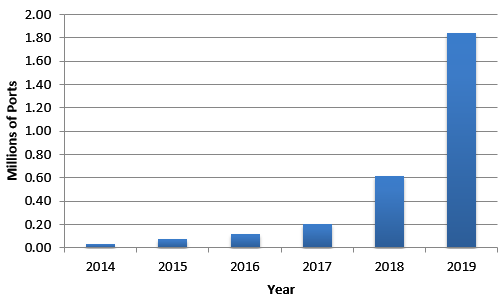
Figure 2: 100 Gigabit Ethernet Port Volume Forecast 2014-2019
While the 400G market is still quite young, we anticipate the growth will be very similar to what we have seen for 100G. However, because this new form factor is based on existing technology, 400G adoption has the potential to grow faster than the 100G market did at its inception.
Below we present a forecast from CIR, which recently released a report on the 400G market. As is mentioned in its report, since it is very early days for 400G, this is “a very tentative forecast.”
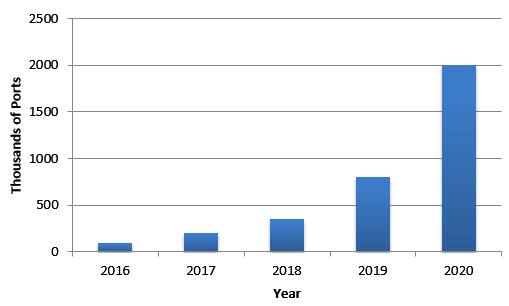
Figure 3: 400 Gigabit Ethernet Port Volume Forecast 2016 – 2020 (Courtesy of CIR)
Lisa Huff, Market Director, Bishop & Associates, Inc.




